I decided to leave Facebook. There were plenty of reasons for this and the last straw was probably a combination of the upcoming changes to WhatsApp's terms and conditions - letting them share more information with the Facebook mothership - and me being in a particularly zealous mood.
I've been thinking of quitting for years; I have not been overly attached to the social aspect and found myself spending less and less time there. One big aspect of the site keeping me from pushing the button was the tagged photos feature: there were hundreds of photos featuring me from the last 12 years during which I went to university, travelled to great places and moved countries - real memories. I didn't want to lose these. Unfortunately, while Facebook provides a way to download your own albums in one big zip, it doesn't include other peoples' photos in which you've been tagged.
After playing around with Facebook's API I thought I'd found the solution, but in the end I realised this still didn't include others' photos. As of writing I don't have a way to automatically grab these, but I thought I'd document my attempt anyway in case it's useful for others later. There is a chance the Facebook API does contain the necessary information in some other part that I didn't check.
Have you found a way to automatically grab others' tagged photos of you? I'd love to hear about it and update the page here for the benefit of others - please get in touch.
Downloading tagged photos from my Facebook profile
Searching the internet for a way to download tagged photos was depressingly, but all too predictably, full of scam apps and ancient scripts that had long since stopped working. Facebook don't make it easy to get these photos, which I assume is intentional. Most of the supposed solutions seem to involve running fragile extensions or scripts inside your browser while you have Facebook open which simulate clicks to sequentially load and save your photos. Giving some random person on the internet the power to do stuff in your browser is dangerous, but the one script that I trusted enough to try turned out not to support downloading of tagged photos, only my own albums which I didn't have a problem getting via the Facebook data dump feature. It was at this point that I stumbled upon a 10 year old script that used the Facebook API itself to grab tagged photos. This seemed promising because APIs are clearly defined ways of getting specific data from web services, not subject to the ephemeral nature of Facebook's HTML. The script required a Facebook API token, which meant first registering to become part of the Facebook developer programme (free and easy) and creating an app. Being a Python guy I rewrote the script and tried running it but found some of the API calls were no longer valid. Even APIs change over 10 years. Luckily after reading the API documentation I was able to figure out what was wrong and fix it - and it worked... or at least I thought it did. The first few photos were clearly photos of me but taken by someone else, so I thought it was working - but upon making a more thorough check I realised these photos were still from my account, so I must have obtained these from the photographers and uploaded them myself. To get a copy of others' photos of me, I concluded I had to do it the hard way: opening up the "Photos of Me" lightbox, clicking "Download" on each one, pressing the right arrow key, and... repeating many hundreds of times. In total I downloaded 500 files this way over the course of about an hour... not something I'd like to repeat, but fortunately I don't have to.
I've documented what I did anyway, in case someone finds a way to make it work for all tagged photos. I've written some instructions below for anyone wishing to attempt it.
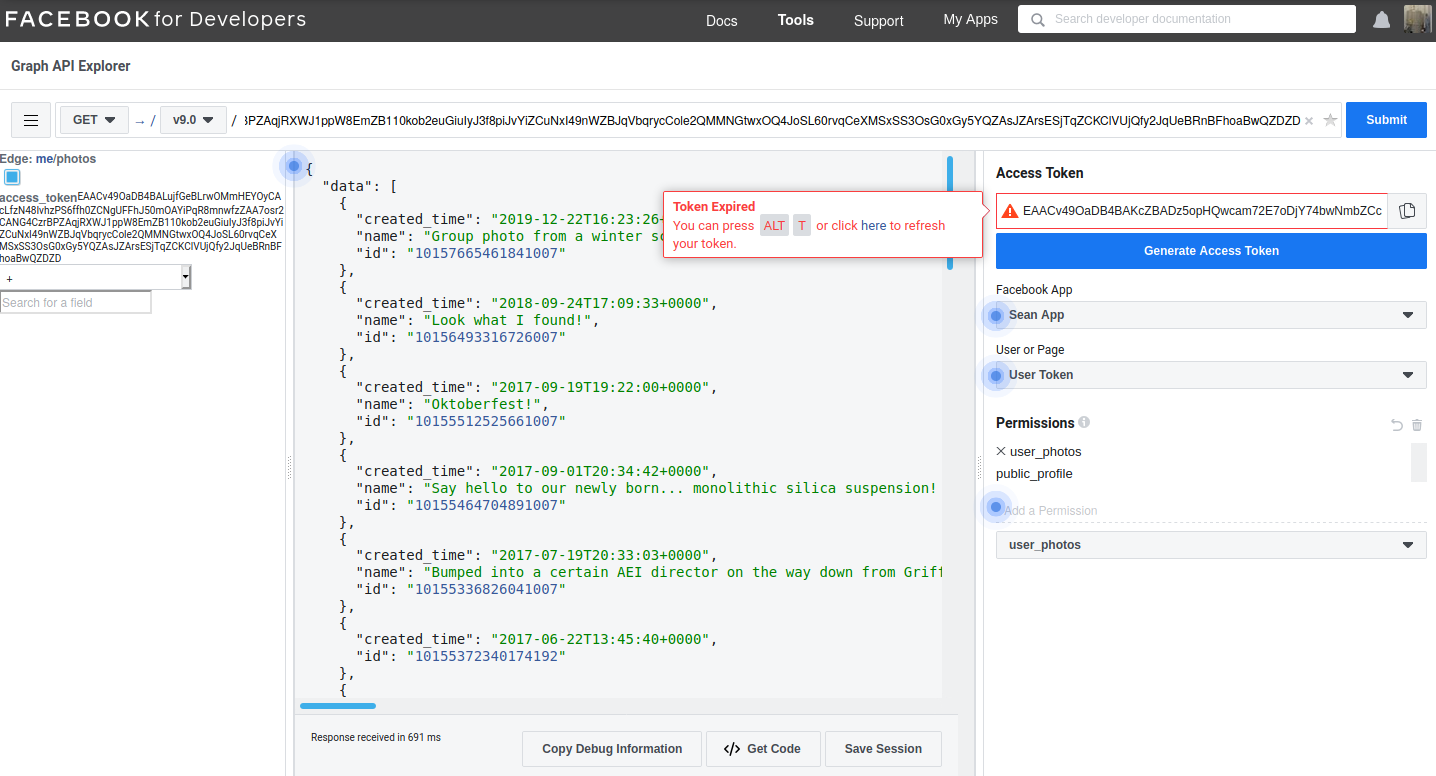
The Facebook API browser. My API token (expired in this picture) let me grab JSON-encoded data, in this case my tagged photos.
Instructions
Doing what I did involves a few steps and will take short while to set up. You'll need a Facebook account (obviously) but also a recent version of Python (at least 3.6) with a library called requests and a system tool available on Linux and OSX called wget. Search the internet for details on how to install these for your operating system. This will still be possible on Windows but will probably need some changes to the final script, which I've not done but are perfectly possible for others to do. In summary, you have to:
- Register as a Facebook developer
- Register a new app
- Specify that the app needs access to photos, and grant it such access for your profile
- Generate an API token
- Run the script using Python
Details for each step below...
Registering as a Facebook developer
You obviously need your Facebook account for this. Follow the handy instructions here.
Register a new app
Go to https://developers.facebook.com/apps/ and click "Create App". A pop-up appears:

Choose "Something Else" then enter a name for the app. I called mine "Sean App" - this is just temporary, and won't ever be released. Leave the other settings as-is and click "Create App". You might be asked to complete a CAPTCHA.
Specify the permissions your app needs
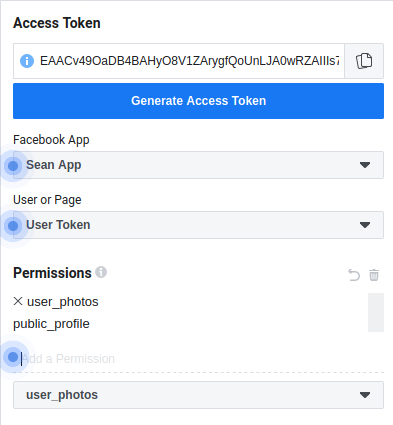
Once you've made your new app, go to the Graph API Explorer. You'll see a random string of letters and numbers under "Access Token" - this is the special token you need to give to the script below to let you access Facebook's data. But this token does not have permission to see photos - so we need to add this as a permission first. Under "Permissions", search for and select "user_photos":
Generate an API token
Click the "Generate Access Token" button and you'll be presented with a screen that will be familiar to you if you've ever linked an app to your profile before:
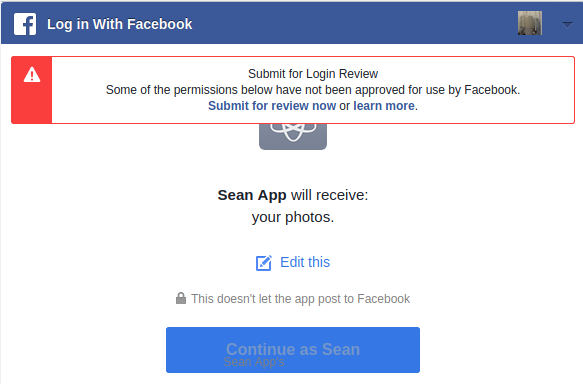
Click "Continue as [x]" where "[x]" is you. This will then give you a new API token on the Graph Explorer page that you can use to grab your photos.
Run the script
Copy the script below into a file on your computer. Edit the ACCESS_TOKEN field to contain the token you generated above, copied from the textbox under "Access Token". Edit the OUTPUT_DIR and PICKLE_FILE paths to whatever you like. On Windows, the /tmp directory doesn't exist, so you'll instead probably have to make that something like C:\Users\[your username]\Desktop\fb after having created the file fb on your desktop. The PICKLE_FILE path is a location where some temporary data will be stored to allow you to resume the script later if it gets interrupted - this can be any location; I put it in the same directory as the output data.
Note
As hinted above, that wget is probably not available on Windows so the line starting os.system might need tweaked to use some Windows HTTP utility. It is surely also possible to use the requests library used elsewhere in the script for this, but since I had wget that's what I used.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | """Facebook tagged photos download script. I, Sean Leavey, hereby release this script into the public domain with no warranty. Sean Leavey https://attackllama.com/2021/01/downloading-tagged-photos-from-facebook/ For help, email me (see https://attackllama.com/contact/). """ import os import pickle import datetime import time import requests SLEEP = 3600 // 200 # One hour / max requests per hour. ACCESS_TOKEN = "replace-with-long-API-token-string" OUTPUT_DIR = "/tmp" PICKLE_FILE = "/tmp/photos.pickle" def fetch(): if os.path.isfile(PICKLE_FILE): print("Using existing photo list") with open(PICKLE_FILE, "rb") as fobj: data = pickle.load(fobj) else: print("Dumping photo list") url = f"https://graph.facebook.com/me/photos" result = requests.get( url, params={"limit": 10000, "access_token": ACCESS_TOKEN} ) result.raise_for_status() data = result.json()["data"] with open(PICKLE_FILE, "wb") as fobj: pickle.dump(data, fobj) ndata = len(data) for i, photo in enumerate(data, start=1): print(f"{i}/{ndata}") imagedate = datetime.datetime.strptime( photo["created_time"], "%Y-%m-%dT%H:%M:%S%z" ) imagepath = f"{imagedate.strftime('%Y%m%d%H%M%S')}-{photo['id']}.jpg" filename = f"{OUTPUT_DIR}/{imagepath}" if os.path.isfile(filename): print(f"Skipping already downloaded file {filename}") continue image_url = f"https://graph.facebook.com/v9.0/{photo['id']}" image_result = requests.get( image_url, params={"fields": ["images"], "access_token": ACCESS_TOKEN} ) image_result.raise_for_status() images = image_result.json()["images"] os.system(f"wget -O '{filename}' '{images[0]['source']}'") print(f"Sleeping for {SLEEP} s") time.sleep(SLEEP) if __name__ == "__main__": fetch() |
Run the script in your favourite Python IDE or with a terminal. It should grab the photos, showing progress as it goes, taking breaks of 18 seconds between each fetch to avoid hitting rate limiting on Facebook's servers. If you have lots of tagged photos then this will run for a while.
It's a quick and dirty script, but it worked for me. If I were polishing this up later I'd use pathlib and maybe add a CLI.
If you use this, please let me know so I can have a warm fuzzy feeling! Or, if you run into problems with the script, I can try to help. Happy scraping!